U-Net: Convolutional Networks for Biomedical Image Segmentation
The U-Net is an architecture for convolutional neural networks consisting of an encoder and decoder with skip connections

Overview
- Previous architectures of convolutional networks failed to preserve high-resolution details
- In a standard encoder-decoder network, data is compressed into a bottleneck where spatial information is lost in favor of high-level semantic meaning
- The breakthrough with this paper was the introduction of skip connections, which skip the bottleneck by concatenating feature maps from the encoding path directly to the feature maps in the decoding path
- Preserves high-resolution information of the input image from the encoding path, so the model no longer has to guess about high-resolution details in the decoding path
- Enables fusion of features so the model can leverage both high-level and low-level information
- Improves gradient flow by propagating gradients from output layer back to earlier layers
Encoder
- Repeated application of:
- Two $3 \times 3$ convolutions, each followed by ReLU
- $2 \times 2$ max pooling operation with stride 2 for downsampling
- Double the number of feature maps at each downsampling stack
Decoder
- Repeated application of:
-
$2 \times 2$ transposed convolution with stride 2 for upsampling
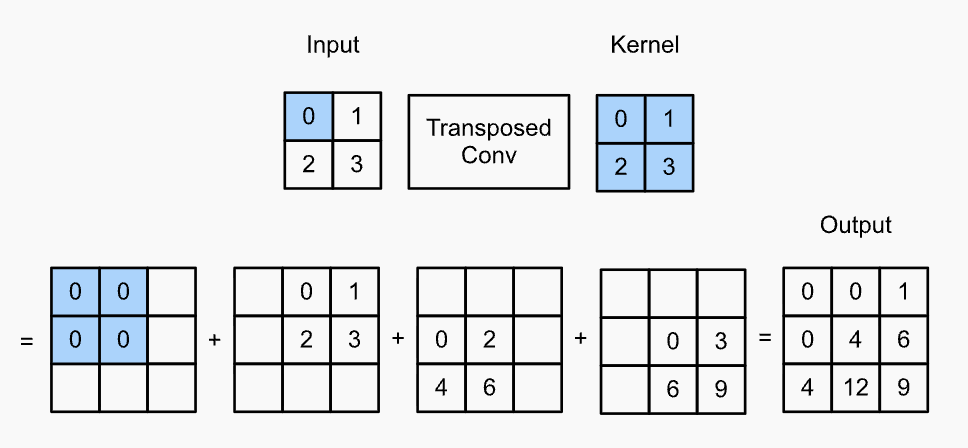
- Concatenation with cropped feature maps from contracting path
- Channel reduction via 3D filters of dimensions $W \times D \times C$ (width, depth, channels)
- Act as weighted combinations of features from multiple channels
- Two $3 \times 3$ convolutions, each followed by ReLU
-
Breakdown
- Concretely in the encoding path of the image above:
- Start with a grayscale image $572 \times 572 \times 1$
- Apply 64 filters of dimensions $3 \times 3 \times 1$ (& ReLU) $\to 570 \times 570 \times 64$
- Apply 64 filters of dimensions $3 \times 3 \times 64$ (& ReLU) $\to 568 \times 568 \times 64$
- Apply $2 \times 2$ max pooling with stride 2 $\to 284 \times 284 \times 64$
- Apply 128 filters of dimensions $3 \times 3 \times 64$ (& ReLU) $\to 282 \times 282 \times 128$
- Concretely in the decoding path of the image above:
- Start at the bottleneck with a feature map of dimensions $28 \times 28 \times 1024$
- Apply 512 transposed filters of dimensions $2 \times 2 \times 1024 \to 56 \times 56 \times 512$
- Concatenate a cropped feature map of $56 \times 56 \times 512 \to 56 \times 56 \times 1024$
- Apply 512 filters of dimensions $3 \times 3 \times 1024$ (& ReLU) $\to 54 \times 54 \times 512$
- Apply 512 filters of dimensions $3 \times 3 \times 512$ (& ReLU) $\to 52 \times 52 \times 512$
- Apply 256 transposed filters of dimensions $2 \times 2 \times 512 \to 104 \times 104 \times 256$
Summary
- Encoding path:
- Spatial dimensions decrease $\to$ loses precise locations & gains global context
- Channel dimensions increase $\to$ gains complex concept detection
- Decoding path:
- Spatial dimensions increase $\to$ recovers spatial resolution
- Channel dimensions decrease $\to$ compresses abstract concepts back into pixels