An Introduction to Convolutional Neural Networks
Convolutional neural networks (CNNs) are a type of neural network which use filters glided across the input to detect patterns in images, video, audio, etc.
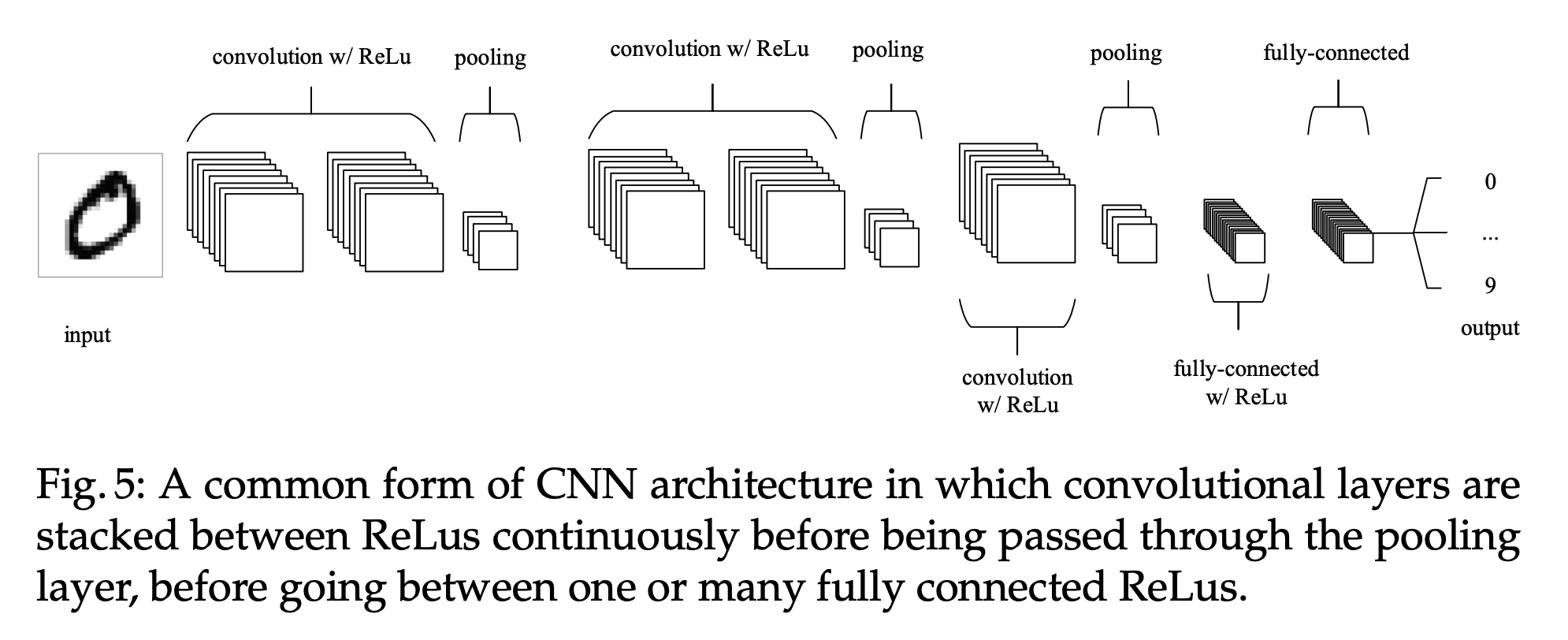
Advantages
- Reduces the number of input nodes (less computation and training time)
- Tolerates small shifts of an image (less overfitting)
- Takes advantage of local spatial correlations in images
Layers
- Convolutional layers: convolve a kernel with the input image
- Pooling layers: downsample the spatial dimensionality
- Fully-connected layers: traditional neural network architecture
Convolutional Layer
- Extracts features from an input image using filters (or kernels):
- Small in spatial dimensionality and are overlaid on top of the image with dimensions $(F * F * D_i)$
- $D_i = 3$ for RGB channels
- $D_i = N$ for the number of filters from the previous layer
- Glided through the input, where the output is the dot product of the input and filter with the addition of a bias term
- Feature maps are then typically fed through a ReLU function: $f(x) = \max(x,0)$
- Small in spatial dimensionality and are overlaid on top of the image with dimensions $(F * F * D_i)$
- The weights and bias of the kernel are adjusted via backpropagation during training
- Each cell in a feature map therefore corresponds to a group of neighboring pixels and the network will learn kernels that fire when they see a specific feature at a given spatial position
- Convolutional layers can significantly reduce the complexity of a model through optimizing three hyperparameters:
- Depth: Number of different kernels convolved across the input volume
- Stride: How many pixels the filter shifts over the input volume at each step of the convolution
- Padding: Extra rows and columns of zeros added to the border of the input image or feature map
- Prevents the feature map from shrinking too rapidly (for deeper networks)
- Preserves information from pixels on the edge
Pooling Layer
- Reduces the dimensionality of the representation by computing some aggregated value over each feature map
- In max pooling, take the largest value in the feature map over the covered area
- The outputs of pooling layers are typically the input of a traditional neural network by flattening the 2D feature maps into a single vector of values and concatenating multiple feature maps